SAE 4 級和 5 級自動駕駛汽車的驗證挑戰, 一直是駕駛模擬專家 rFpro 公司的主要關注點,fFpro技術總監 Chris Hoyle 表示,網聯自動駕駛汽車的出現為汽車行業帶來了一系列新的未知數。未來,汽車制造商必將建立包含數千個模擬測試場景的數據庫,以應對汽車驗證的挑戰。
Hoyle 認為,目前必須回答的關鍵問題包括:我們如何才能確定網聯自動駕駛汽車可以在任何條件下都可安全運行?我們該如何保證測試的全面性和嚴謹性,但又同時滿足對測試周期和成本要求?我們是否有方法在進入驗證階段前,加速自動駕駛車輛的開發,但又同時避免給公共道路用戶帶來危險?
Hoyle 表示自己經常遇到相關討論。他認為,與現實世界中的真實測試相比,模擬仿真測試具有覆蓋范圍大、測試周期短等優勢,但前提是必須加以正確應用。
新的模擬仿真平臺
rFpro 公司聲稱已經推出了世上首款針對自動駕駛汽車模擬仿真、訓練及開發的商用平臺,可以在“各種可以想象到的環境下”對自動駕駛汽車進行測試。據稱,該平臺的一個關鍵特點是“以非常高的精度,精確復制現實世界的測試環境”。通過一項為期 3 年的項目,rFpro 公司已經利用高精度掃描技術(更多信息,請點擊這里)將大量真實道路轉換為模擬測試場景,并最終創建了一個“模擬測試庫”。用戶可在庫中選擇各種不同的模擬測試場景,并控制從“天氣”到“行人”等各種變量輸入。目前,這項技術已被 2 家大型OEM、3 家自動駕駛汽車開發商及 1 條無人駕駛賽車產品線所采用,但出于商業機密方面的考慮,rFpro 公司并未透露更多細節。
憑借一組全天候工作的計算機,制造商每月可累計數百萬英里的模擬測試里程。Hoyle 解釋說:“從統計學角度而言,人類駕駛員平均每行駛 1 億英里,就會發生一起交通致死事故(來源:NHTSA數據),但我們在自動駕駛汽車的模擬測試中很難真正累計到這種級別的測試里程數。事實上,人類駕駛員的“數據”如此優秀是因為:在日常駕駛中,我們的絕大多數里程都是“無事發生”的。正因如此,我們可以消除這部分“無事故”里程,并通過模擬技術讓網聯自動駕駛汽車每隔幾秒鐘即遇到一次“千年一遇”的事件,進而大幅縮短模擬測試周期。未來,汽車制造商將建立包含數千個模擬測試場景的數據庫,而自動駕駛汽車必須成功通過這些測試場景,才能通過驗證。”
每次遇到測試失敗的情況,模擬測試場景庫中都會新增幾項針對這一場景的標準測試。此外,車輛不僅必須成功通過每一項測試,而且還必須保證性能的穩定。
Hoyle 表示,這種采用回歸邏輯不斷重復運行的測試庫,可以確保任何對自動駕駛汽車的新改進均不會影響現有功能。“為了實現這個目的,rFpro 不僅可以在一組設備上并行運行多個實驗,而且還可在多個 CPU 和 GPU 上對一項實驗進行擴展,從而應對由于自動駕駛汽車數據來源多樣(包括多部攝像頭、激光雷達、雷達傳感器等)而引入的復雜性。”
標準化模擬
程度如此密集的測試需要一定時間才能達到預期的結果。但 Hoyle 預計,未來五年中,新測試場景的增加速度將降至在統計學角度低于人類駕駛員出錯率的程度。這時,現實世界中的真實物理驗證流程就可以啟動了。
Hoyle 認為,如果進展理想,汽車行業將開發一套全球性的標準化測試場景庫,任何自動駕駛車型一旦通過該標準庫的驗證,即可進入下一階段測試——即從庫里抽樣選擇一部分場景,進行現實世界中的真實測試。
但這就帶來了另一個問題:我們如何才能保證這個場景庫的全面性和嚴謹性? Hoyle 表示,諷刺的是,人類非常善于測試自動駕駛汽車,“因為人類具有隨機且不可預知的特點,從來不會重復;人類會犯錯,而且表現也會隨著情緒和疲勞程度的不同而改變。”目前,單個模擬測試中可以支持的人類駕駛員數量已經增加至 50 個。我們可以測試自動駕駛汽車在人口或道路用戶密集的城市中心地區的表現,而且無需承擔人員傷亡的風險。
rFpro 公司預計,到今年晚些時候,加入單獨測試的人類駕駛員數量將增加至 250 名,負責對一輛或多輛網聯自動駕駛汽車的測試。
人工智能 (AI) 系統的高效開發,離不開在啟動重新測試前從失敗中進行學習、總結、改進的能力。Hoyle 強調說,我們還會將頻繁遇到的邊緣案例(其中一個參數超過系統限制)或極端案例(其中兩個或兩個以上參數超過系統限制)反饋至系統中,從而不斷豐富系統的知識庫。
我們可以建立訓練數據庫,用以展示失敗測試中本應表現出來的正確行為,且每個數據庫均應包含來自所有傳感器模型的數據,包括虛擬攝像頭、激光雷達和雷達。Hoyle 表示,每一幀訓練數據均應與“地面實況”數據相關聯,包括語義段、實例段、光流算法、深度和標記目標數據,“在這種邏輯下,我們的模型可以通過監控下的學習,針對每一種新的失敗模型,進行相應的改進和適應。”
然而Hoyle 也補充道,盡管如此,我們還有一個至關重要的因素必須始終銘記于心, “人類是無偏差輸入的最佳來源,因為即使在相同天氣條件下的同一條道路上,人類駕駛員也不會以完全相同的方式駕駛。此外,他們可以發現一些異常、激怒或意外事件,并有可能因為其他道路用戶的行為而作出不當反應!”
The challenges of validating autonomous vehicles designed to operate at SAE Level 4 and 5 are a major focus of driving-simulation specialist rFpro. The advent of connected autonomous vehicles (CAVs) presents the auto industry with a broad new set of unknowns that will see automakers establish "libraries" of thousands of test scenarios, said the company’s technical director, Chris Hoyle.
He presents key questions that have to be answered: “How will we know that a CAV is safe to operate under all conditions? How can we ensure that testing is sufficiently comprehensive and rigorous, yet timely and cost-effective? Even before we reach the validation stage, is there a way to accelerate the development of autonomous vehicles without the risks associated with exposing them to public road users?”
Hoyle said he is routinely exposed to this debate and believes that simulation can provide greater scope and shorter timelines than physical testing—but that it must be applied correctly.
New simulation platform
The company has launched what it claims to be the world’s first commercially available platform to train and develop autonomous vehicles in simulation and test their systems in “every scenario imaginable.” A key aspect of the platform is claimed to be the level of simulation accuracy achieved replicating the real world. A three-year program has seen the company build a library of real roads via high-precision scanning technology (see previous article). Users have control of a wide range of variables, from weather to pedestrians. The technology has been adopted by two large OEMs, three autonomous-vehicle developers and a driverless motorsport series. For commercial confidential reasons, rFpro is unable to give further details.
By using a cluster of computers 24/7, manufacturers can achieve millions of simulated miles of testing every month. Explains Hoyle: “Human drivers average one fatality in 100 million miles driven (source: www-fars.nhtsa.dot.gov/Main/index.aspx), but we cannot realistically attempt to accumulate this sort of mileage with a CAV before declaring a test to be complete. The reason a human driver scores so well is because much of the distance is uneventful; by eliminating this ‘dead’ mileage and subjecting—via simulation—the CAV to a “once-in-a-1000 year” event every few seconds, we can massively compress the timescale. Vehicle manufacturers will build libraries of thousands of simulated test scenarios, which autonomous models will have to successfully pass before they will be considered ready for validation.”
Any failed experiment typically results in several more standard tests being added to the library of simulated scenarios, each of which must be reliably passed with consistency.
Hoyle said the libraries of tests, run continuously using a regression process, would ensure that any new developments to an autonomous model do not break existing functionality. “To enable this, rFpro not only scales across a cluster of machines to run multiple experiments in parallel, but it also allows each experiment to scale across multiple CPUs and GPUs to cope with the complexity of autonomous models fed by multiple camera, LiDAR and radar sensors.”
Standardizing simulation
Testing so intensively will take time to achieve required results. But Hoyle anticipates that over the next five years, the rate at which new test scenarios are identified will fall to the point at which it can be statistically proven to be below the error rate for human drivers. At that stage, the physical validation and verification process could begin.
He expects—perhaps hopefully—that the auto industry will develop a global standardized library of test scenarios which, once the model validates them, will then move forward to the next stage: a statistical sample of those tests will be selected and expanded for physical testing in the real world.
But along comes another question: how to build a library of tests that is sufficiently comprehensive and rigorous. Ironically, Hoyle stated that humans are very good at testing autonomous vehicles: “Humans are random, unpredictable, never the same twice; we make mistakes and our performance changes with mood and fatigue level.” At present, up to 50 human drivers can be added into a single simulated experiment, piloting vehicles with the autonomous model tested in densely-populated, simulated urban environments surrounded by other road users and pedestrians, without any risk of death or injury.
By late this year, rFpro anticipates this will be scaled up to 250 human test drivers entering a single experiment, shared by one or more CAVs.
Efficient development of artificial-intelligence (AI) systems requires the ability to learn from failures and improve the functionality before re-testing, stressed Hoyle, saying edge cases (where one parameter exceeds system limits) or corner cases (where a combination of two or more parameters exceeds system limits) frequently will be encountered and fed back into the system, increasing its knowledge base.
Training datasets can be established to demonstrate correct behavior for failed experiments, each comprising all the data that is fed to sensor models for virtual cameras, LiDAR and radar. Every frame of training data is associated with “ground-truth” data, comprising semantic segmentation, instance segmentation, optical flow, depth and labelled object data: “In that way, through supervised learning, the models improve and adapt to each new failure mode,” Hoyle said.
But through all this, a vital factor must always be remembered and appreciated, he added: “Humans are the best source of unbiased inputs because they never drive in an identical manner, even when repeating a journey on the same road in the same weather conditions. Also, they can identify behavior which is unusual, irritating or unexpected and likely to promote adverse reaction from other road users!”
Author: Stuart Birch
Source: SAE Automotive Engineering Magazine
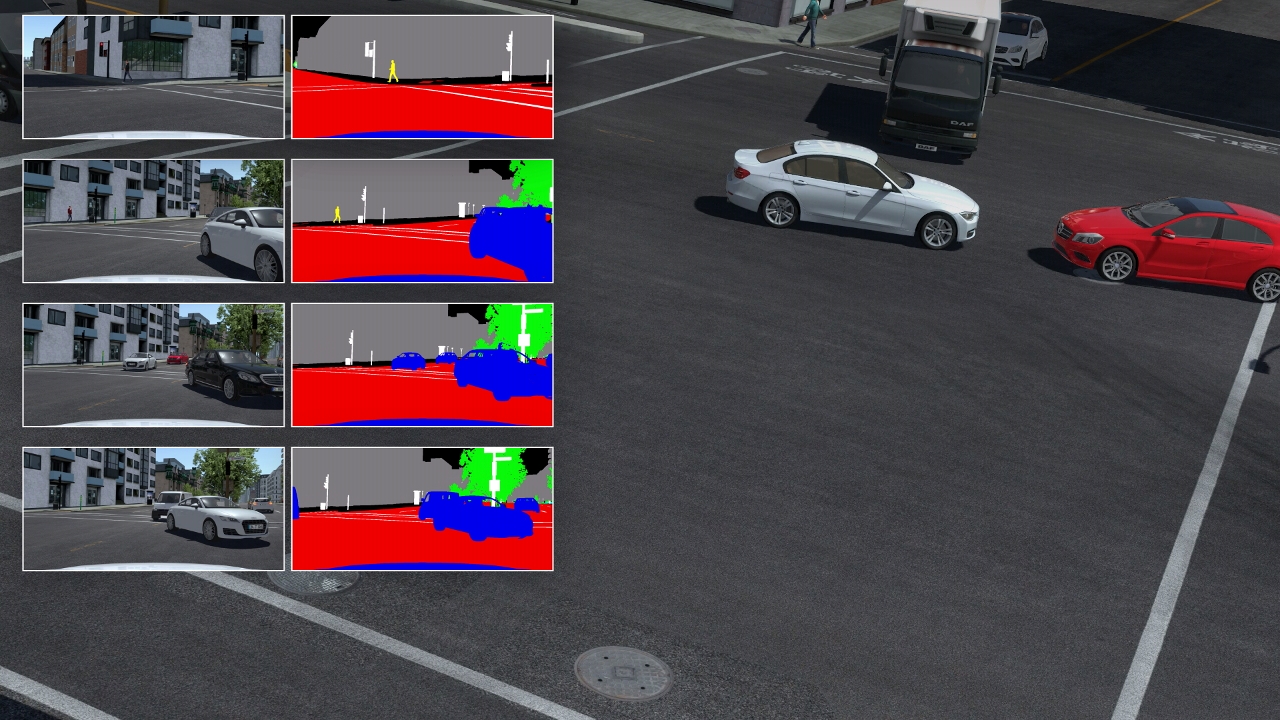 圖為在fPro 中為一個缺少道路標記的交叉路口創建訓練數據集的復雜案例。(圖片來源:rFpro)
圖為在fPro 中為一個缺少道路標記的交叉路口創建訓練數據集的復雜案例。(圖片來源:rFpro) rFpro 公司正在巴黎的一個十字路口進行測試,可以看到這個十字路口的道路標記比較模糊。(圖片來源:rFpro)
rFpro 公司正在巴黎的一個十字路口進行測試,可以看到這個十字路口的道路標記比較模糊。(圖片來源:rFpro) 每一幀用于監控學習的訓練數據均包括語義段、實例段、光流算法、深度和標記目標數據,圖為一個語義分割的例子。(圖片來源:rFpro)
每一幀用于監控學習的訓練數據均包括語義段、實例段、光流算法、深度和標記目標數據,圖為一個語義分割的例子。(圖片來源:rFpro)